새벽에 메신저 알람이 울렸습니다. 사내 기간계(보험 Core) 서비스의 프로세스가 갑자기 죽었다는 알람입니다. 생각해보니 최근 JDK와 프레임워크 버전을 업그레이드한 이후로 이런 일이 발생하고 있었습니다.
모니터링 그래프를 보는 순간, 문제의 심각성을 깨달았습니다. Java Heap Size를 20GB로 설정했는데, 실제 메모리 사용량은 40GB를 훌쩍 넘어 계속 증가하고 있었습니다. Metaspace나 다른 JVM 내부 영역을 고려해도 말이 안 되는 수치입니다.
"이건 Heap 문제가 아니야."
JVM 내부가 아닌 Native Memory 에서 뭔가 새고 있다는 확신이 들었습니다.
문제의 원인을 찾고 해결한 과정을 공유합니다.
문제 서버 상황
- OS: IBM AIX 7.5
- JDK: IBM Semeru OpenJDK 11.0.22
- Java Max Heap Size: 20GB
- 핵심 증상: Heap Size(20GB)를 훨씬 초과하는 메모리 사용
- 변경사항: JDK 버전 업그레이드(IBM 상용 JDK 1.6 -> IBM Semeru OpenJDK 11.0.22)
원인파악의 어려움
HotSpot이 아닌 OpenJ9의 세계
문제는 환경이었습니다. 기간계 서버는 IBM AIX 7.5 OS에서 IBM Semeru OpenJDK 11.0.22를 사용하고 있었습니다. 이 JDK는 일반적으로 많이 쓰는 HotSpot VM 기반이 아닌 OpenJ9 VM 기반입니다.
HotSpot VM 환경이었다면 jcmd 명령어 하나로 간단한 스케쥴 스크립트를 만들어서 Native Memory 영역을 추적할 수 있었을 겁니다.
# HotSpot VM 이었다면 이렇게 쉽게 할 수 있었을 텐데...
> */5 * * * * jcmd $(pgrep -f myapp) VM.native\_memory summary > /logs/nmt\_$(date +\\%Y\\%m\\%d\_\\%H\\%M).log하지만 OpenJ9에는 NativeMemoryTracking 옵션 자체가 없었습니다. 대신 -Xdump, -Xverbosegclog 와 같은 표준 옵션을 추가한 후 javacore dump를 생성해야 했는데, 이게 문제였습니다.
프로덕션에서 dump를 계속 떠야 한다고?
javacore dump는 한 번 생성할 때마다 수십 MB에서 수백 MB의 파일을 만들어냅니다.
프로세스 전체 상태를 디스크에 기록하는 작업이라 수백 ms에서 수십 초가 걸립니다.
5분마다 이런 작업을 한다면? 하루에 288개의 dump 파일이 쌓이고, 디스크 I/O는 끊임없이 발생하며, STW(Stop-The-World)까지 걸릴 수 있습니다.
운영 중인 기간계 서비스에서 이런 부담을 감수하기는 어려웠습니다.
AIX라는 또 다른 장벽
Linux였다면 jemalloc이나 perf 같은 도구들을 사용할 수 있었을 겁니다. 하지만 AIX는 Unix 기반 OS로, 대부분의 오픈소스 프로파일링 도구가 지원하지 않았습니다.
결국 저는 사용중인 상용 APM 을 활용하여 문제를 해결할 방법이 있는지 고민했습니다.
APM 벤더와의 협업
당시 사용하던 APM은 기본적인 Native Memory 총량은 확인할 수 있었지만, 어디서 새는지는 알 수 없었습니다. 우리에게 필요한 건 더 세밀한 추적이었습니다.
APM 벤더의 기술지원팀에 상세한 요구사항을 전달했습니다.
[기술 지원 요청 내용]
환경: IBM Semeru OpenJDK 11.0.22 (OpenJ9) on AIX 7.5
문제: Native Memory Leak으로 인한 프로세스 종료현황:
- OpenJ9 표준 도구로는 추적 불가
- javacore dump는 프로덕션에서 주기적 사용 어려움
- 현재 APM으로는 메모리 증가 감지만 가능, 원인 파악 불가요청사항:
- Native Memory 영역별 세분화 추적 (ZIP/GZIP, NIO, Thread Stack 등)
- OpenJ9 VM 환경에서의 정확한 메모리 측정
- 실시간 추적이 가능하면서도 성능 오버헤드 최소화
여러차례 기술검토 회의를 거듭한 결과 APM 벤더는 우리를 위한 맞춤형 패치를 개발해주었습니다.
강화된 추적 기능
새로운 APM 에이전트는 JNI를 통해 Native 메모리 할당과 해제를 후킹하고, java.util.zip.Inflater와 Deflater의 생성과 소멸을 추적했습니다. DirectByteBuffer의 할당도 기록했습니다. 무엇보다 샘플링 기반 수집으로 성능 영향을 1% 미만으로 유지했습니다.
APM 에이전트 설정 (강화 패치 버전)
apm.native.memory.track_nio_buffer=true # Direct ByteBuffer 상세 추적
apm.native.memory.track_zip_inflation=true # ZIP/GZIP Inflater/Deflater 추적
apm.native.memory.track_deflater=true # Deflater 객체별 메모리 추적
apm.native.memory.track_thread_stack=true # Native Thread Stack 추적
apm.native.memory.track_code_cache=true # JIT 컴파일 코드 캐시 추적
apm.native.memory.sampling_interval=60000 # 1분 간격 샘플링 (오버헤드 최소화)
원인 분석
패치된 APM을 프로덕션에 적용하고, 드디어 대시보드에서 문제의 원인을 명확하게 볼 수 있었습니다.
[시간별 Native Memory 증가 추이]
00:00 - ZIP Deflation: 0MB
06:00 - ZIP Deflation: 10GB
12:00 - ZIP Deflation: 25GB
18:00 - ZIP Deflation: 45GB
20:00 - OOM Killer 작동, 프로세스 종료
NIO Direct Buffer나 Thread Stack은 정상 범위 내에서 조금씩만 증가했지만, ZIP/GZIP 처리 관련 메모리만 급격하게 증가했습니다.
상세 로그를 보니 특정 API 호출 패턴까지 포착되었습니다.
[APM - Native Memory Detail Log]
Memory Type: ZIP_Deflation
Allocated: 15,234 MB
Object Count: 3,421 Deflation instances
Leak Suspected: YES
Top Allocation Site: com.hwgi.core.util.CompressionUtil.compress()
원인을 찾았습니다. 하지만 왜 이런 일이 생긴 걸까요?
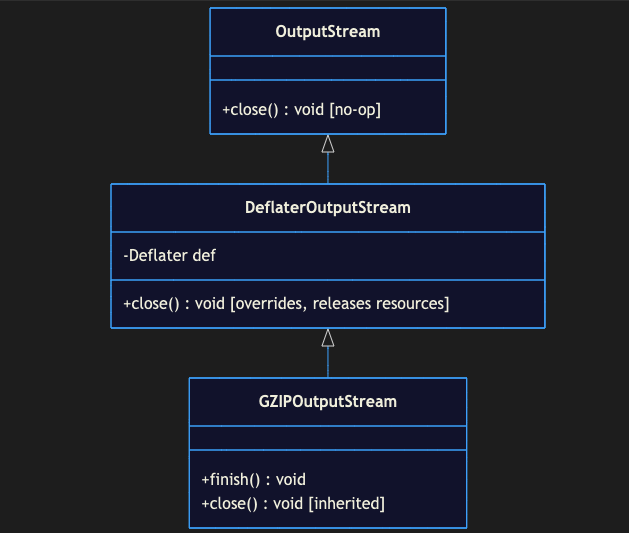
GZIPOutputStream 구조
문제의 코드 내부에서는 GZIP 압축을 위해서 GZIPOutputStream을 선언에 활용하고 있었습니다. 먼저 GZIPOutputStream 클래스 다이어그램을 살펴보겠습니다.
코드를 열어보니 다음과 같은 패턴이 있었습니다.
// 문제의 코드
GZIPOutputStream gzipOut = new GZIPOutputStream(out);
gzipOut.write(data);
gzipOut.finish();
// close() 호출 누락finish()는 호출했지만 close()는 호출하지 않았습니다.
결론부터 말하자면, close()를 호출해야만 내부적으로 Deflater의 end()를 호출해서 사용중인 Native Memory 리소스가 해제됩니다.
그렇다면 왜 JDK 업그레이 전에는 이러한 문제가 발생하지 않았을까요?
놀랍게도 close() 호출이 누락된 위 코드는 15년 동안 문제없이 돌아갔습니다. IBM J9 VM 1.6.0 환경에서는요.
JDK 소스 디버깅
IBM J9 VM 1.6.0의 GZIPOutputStream.finish() 구현을 디컴파일해보니 이런 코드가 있었습니다.this.def는 Deflater 객체를 가리킵니다.
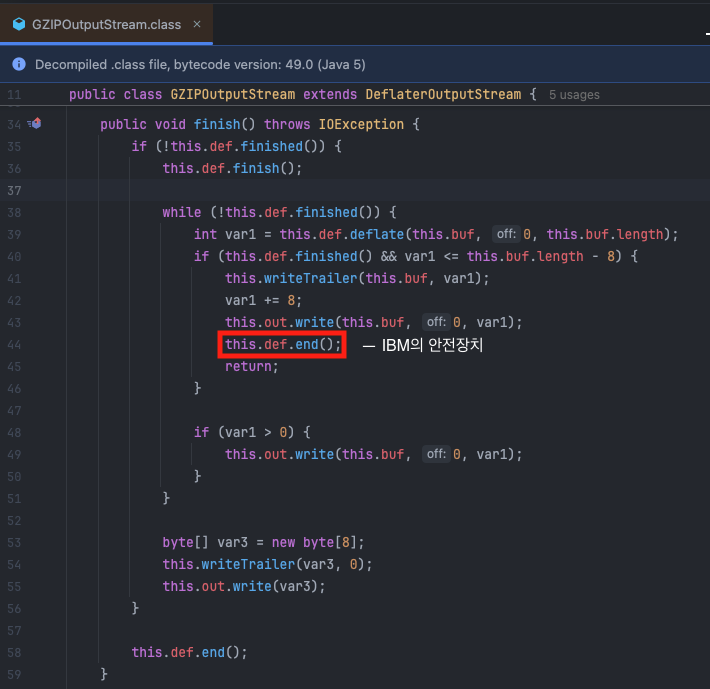
finish() 메서드가 압축을 완료한 후 즉시 def.end()를 호출해서 Native memory를 해제했습니다. close()를 호출하지 않아도 메모리 누수가 발생하지 않았던 거죠.
하지만 IBM Semeru OpenJDK 11.0.22의 구현은 달랐습니다.
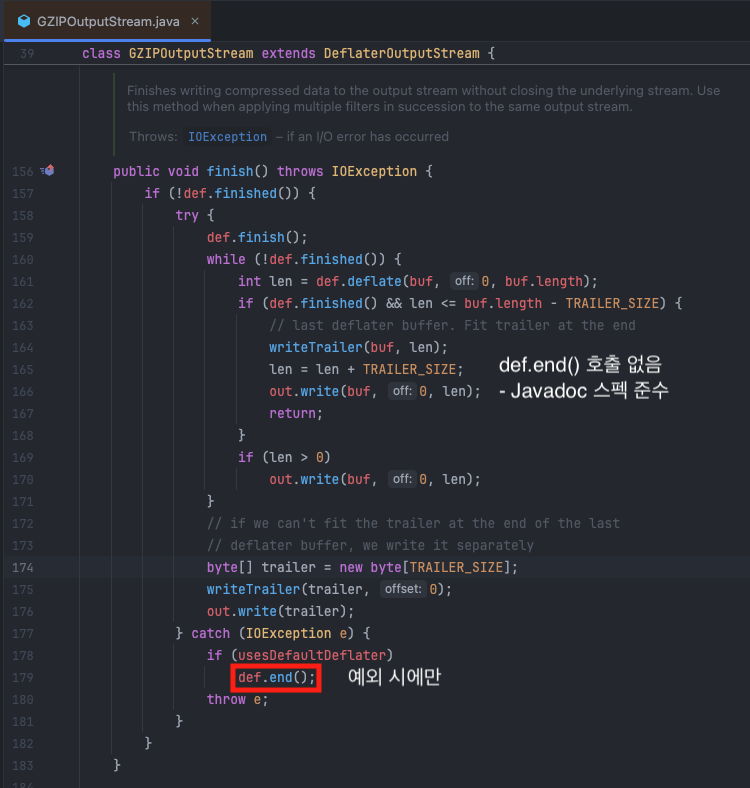
finish()는 압축만 완료하고 def.end()를 호출하지 않습니다. Native memory 해제는 close() 메서드에 위임되어 있었습니다.
JDK 구현의 역사: 왜 IBM의 안전장치가 사라졌을까?
IBM Semeru OpenJDK는 OpenJ9 VM에 OpenJDK의 표준 Class Library를 결합한 것입니다. IBM이 수십 년간 축적한 엔터프라이즈 안정성 패치들이 OpenJDK의 표준 구현으로 교체되면서, 이런 방어적 패치들이 사라진 겁니다.
OpenJDK의 설계 철학은 Javadoc 명세를 충실히 따르는 것이었습니다. finish() 메서드의 Javadoc에는 "without closing the underlying stream" 이라고 명시되어 있습니다. 스트림을 닫지 않고 여러 압축 블록을 순차적으로 쓸 수 있도록 하기 위한 설계였죠.
// finish()가 스트림을 닫지 않아야 하는 경우
FileOutputStream fos = new FileOutputStream("data.gz");
// 첫 번째 압축 블록
GZIPOutputStream gzip1 = new GZIPOutputStream(fos);
gzip1.write(data1);
gzip1.finish(); // 압축만 끝내고 fos는 열린 상태 유지
// 같은 파일에 두 번째 압축 블록 추가
GZIPOutputStream gzip2 = new GZIPOutputStream(fos);
gzip2.write(data2);
gzip2.close(); // 마지막에만 closeIBM의 철학은 "현실의 불완전한 코드도 안전하게 동작해야 함"이었다면, OpenJDK의 철학은 "스펙대로 사용하지 않으면 문제를 드러내야 함"이었습니다.
두 가지 설계 철학의 충돌
IBM의 접근법: 방어적 프로그래밍
- 대규모 엔터프라이즈 시스템의 장시간 운영 경험 반영
finish()만 호출하고close()누락하는 레거시 코드 보호- 은행, 보험 등 미션 크리티컬 시스템의 안정성 최우선
- 잘못된 코드 패턴을 묵인하고 보호
OpenJDK의 접근법: 표준 준수
- Javadoc 명세 충실 준수
- 스트림 체이닝 지원 (여러 압축 블록을 하나의 스트림에 순차 작성)
- 개발자의 명시적 리소스 관리 책임
- 잘못된 코드는 문제를 일으켜야 수정 유도
해결과 교훈
코드 수정
답은 간단했습니다. try-with-resources를 사용해서 자동으로 close()가 호출되도록 하는 것.
// Before (문제 코드)
GZIPInputStream gzipIn = new GZIPInputStream(in);
// ... 사용 후 close() 누락
// After (수정 코드)
try (GZIPInputStream gzipIn = new GZIPInputStream(in)) {
// ... 사용
} // try-with-resources로 자동 close()코드를 수정하고 배포한 후, 메모리는 안정적으로 유지되었습니다.
"작동하는 코드 ≠ 올바른 코드"
이번 경험을 통해 배운 가장 큰 교훈은 이것이었습니다. 우리의 코드는 15년 동안 "작동"했지만, 결코 "올바른" 코드는 아니었습니다. IBM JDK의 방어적 패치가 우리의 잘못된 코드를 감춰주고 있었을 뿐이죠.
[시간별 문제 발생 과정]
IBM J9 VM 1.6.0 (1990년대~2010년대):
→ finish()에서 def.end() 자동 호출
→ 15년 이상 프로덕션 운영, 메모리 누수 없음
→ 잘못된 코드지만 IBM의 안전장치로 보호됨
IBM Semeru OpenJDK 11.0.22 (2010년대~):
→ finish()에서 def.end() 호출 안 됨
→ 숨어있던 버그(close() 누락)가 드러남
→ Native Memory 누수 → 20시간 후 프로세스 종료결과적으로 OpenJDK로의 전환은 이런 기술 부채를 청산하는 과정이었습니다.
후속 조치
Heap 메모리만 보면 안 됩니다. Native Memory도 반드시 모니터링해야 합니다. 특히 압축, 암호화, NIO 같은 Native 영역을 사용하는 API들을 많이 쓴다면 더욱 그렇습니다.
지금 우리 대시보드에는 Heap과 Native Memory 추이가 함께 표시되고, NIO Buffer, ZIP, Thread Stack 등의 항목이 시간대별로 차트로 나타납니다. Native Memory가 30GB를 넘으면 조기 경보가 울리도록 설정했습니다.
Before: 사후 대응
- 프로세스 재기동 시점마다 단순 알람
- 원인 파악 불가
After: 사전 예방
- OOM Killer 발생 전 Native Memory 증가 알람
- 임계값 기반 사전 경보 (예: Native > 30GB 시)
대시보드 구성
메모리 추이 시각화
- Heap vs Native Memory 추이 그래프
- NIO Buffer, ZIP, Thread Stack 등 항목별 차트
- 시간대별 증가율 표시
마치며
상용 JDK에서 OpenJDK로의 변화는 생각보다 고려해야할 것이 더 많다는 점을 느꼈습니다. 사내 개발환경에서 여러가지 제약사항이 있으나 최대한 할 수 있는 부분들을 찾아서 조금씩 개선하고 있습니다. 또 개인적으로는 변화를 적극적으로 수용하고 대응할 능력을 갖추는 것이 중요하다고 생각합니다.
이번 경험을 통해 저는:
- 더 탄탄한 코드를 작성하게 되었고
- 더 세밀한 모니터링 체계를 갖추게 되었으며
- OpenJ9 + AIX라는 특수한 환경에서도 효과적으로 문제를 추적할 수 있는 기반을 마련했습니다
원인을 파악하고 조치하는데 꽤 많은 시간이 걸렸지만, 그 과정에서 배운 것들은 훨씬 값졌습니다.
참고 자료
'Java' 카테고리의 다른 글
| 스레드 풀(Thread pool) 제대로 이해하기 (0) | 2023.09.10 |
|---|---|
| Java에서 Enum 의 비교는 '==' 인가? 'equals' 인가? (1) | 2022.03.20 |
| 자바와 다중상속 문제 (0) | 2022.01.08 |
| 자바8 람다식의 등장 (0) | 2022.01.02 |
| 동기화(synchronization)와 Thread Safe 제대로 이해하기 (5) | 2021.12.26 |




댓글