Thread per request model
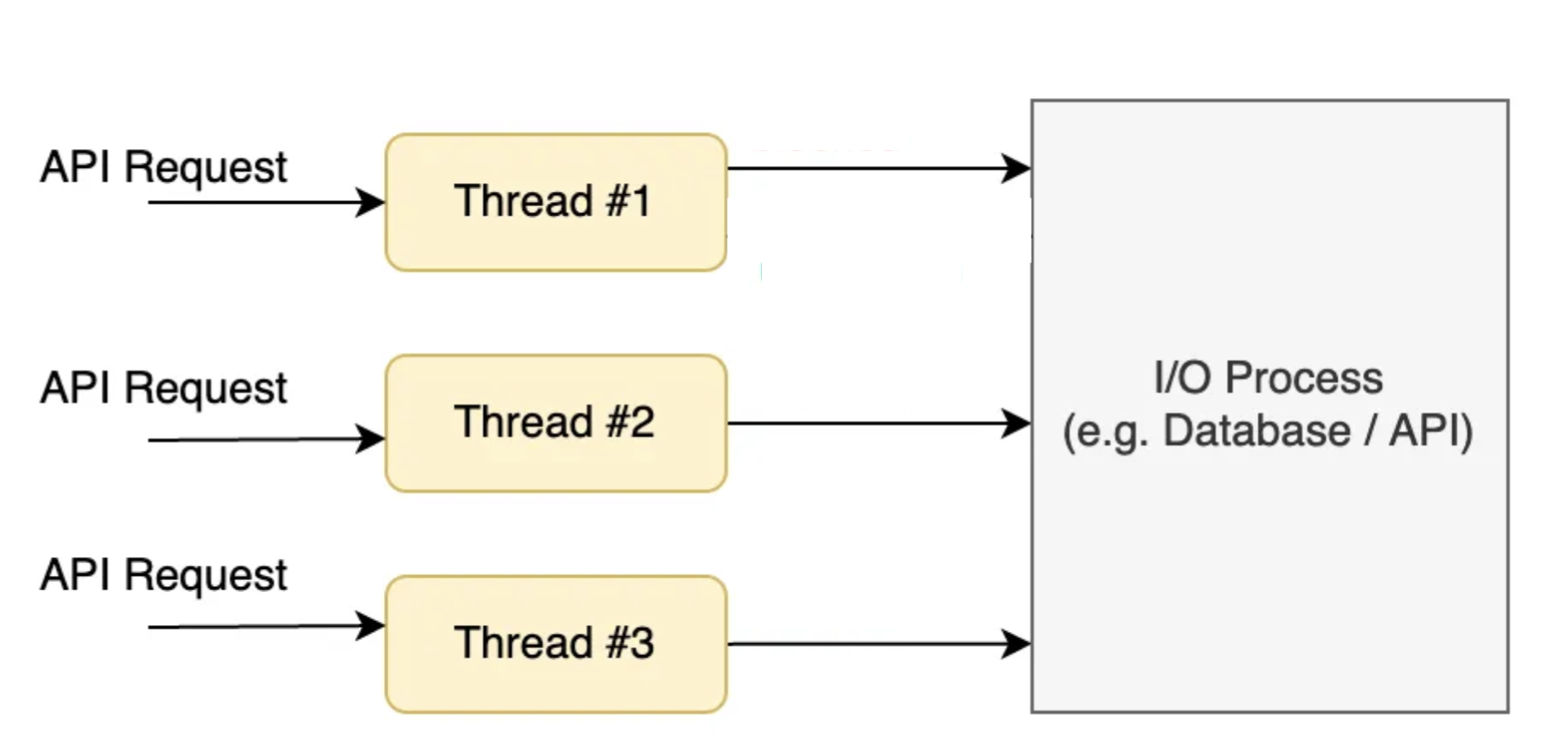
백엔드 API 서버에서 요청을 처리하는 여러가지 방식이 있는데 그 중 하나가 Thread per request model 이다.
Thread per request model 에서는 하나의 API Request 는 하나의 Thread가 처리하게 되는 구조다.
만약 Thread per request 모델의 동작 방식이 서버에서 들어오는 요청마다 스레드를 새로 만들어서 처리하고 처리가 끝난 스레드는 버리는 식으로 동작한다면 어떤 문제점이 있을까?
우선 스레드 생성/수거 작업은 OS의 kernel 레벨에서 이루어지는 꽤나 비싼 작업이다.
따라서 요청이 올때마다 스레드를 생성하게 되면 스레드 생성에 소요되는 시간 때문에 요청 처리가 더 오래 걸릴 것이다.
또한 요청마다 스레드를 생성하는 경우에 API 처리 속도보다 더 빠르게 요청이 늘어나게 되면 아래와 같은 문제들이 발생한다.
- 스레드가 계속 생성됨 -> 스레드가 수 증가 -> 메모리가 점점 고갈됨
- 컨텍스트 스위칭이 더 자주 발생 -> CPU 오버헤드 증가(CPU time 낭비)
- 어느 순간 서버 전체가 응답 불가능 상태에 빠질 수 있음
Thread Pool
위 문제를 해결하는 Thread Pool 이란 개념이 등장한다.
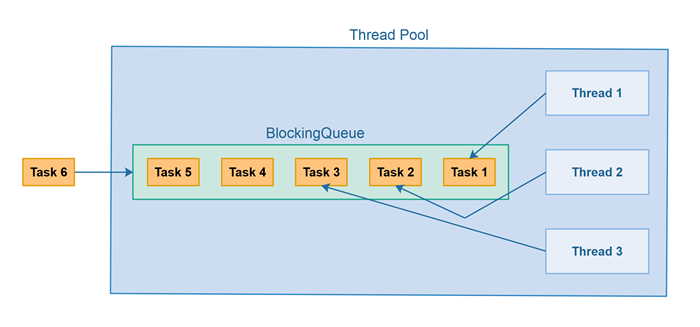
스레드 풀은 미리 스레드를 여러 개 만들어 놓고 재사용 하는 방식으로 스레드 생성 시간을 절약하는 것이다.
Thread Pool은 작업 처리에 사용되는 스레드를 제한된 개수만큼 정해 놓고 작업 큐(Queue)에 들어오는 작업들을 일이 없는 스레드가 맡아 처리한다. 처리가 다 끝난 스레드는 수거되는 것이 아니라 다시 스레드 풀로 돌아오고 다음 작업을 대기한다.
이런 방식을 통해 제한된 개수의 스레드를 운용하며 스레드가 무제한으로 생성되는 것을 방지함으로써 시스템 전체에 문제가 생기는 것을 방지한다.
스레드 풀에 몇 개의 스레드를 만들어 두는게 적절할까?
여러 가지 상황을 고려해야 하는데 CPU의 코어 개수와 스레드 풀에 할당될 task의 성향에 따라 적절한 스레드 개수는 달라진다.
- CPU-bound task: 코어 개수 만큼 혹은 그 보다 몇 개 더 많은 정도가 적절하다. 많은 스레드 수를 추천하지 않는 이유는 컨텍스트 스위칭 관점에서 고려했기 때문이다.
코어에서 실행되던 CPU 작업을 수행하던 스레드가 다른 스레드로 바뀔 때마다 컨텍스트 스위칭을 하게 되는데 이 컨텍스트 스위칭 역시 CPU 코어에서 실행되는 작업이다. 따라서 고정된 CPU의 코어 개수에서 스레드 수를 계속 늘리면, 각 코어에서 경합하는 스레드 수가 점점 많아질 것이고 이로 인해 overhead가 증가하여 성능 면에서 한계가 발생한다. - IO-bound task: 코어 개수보다 1.5배 ~ 3배 정도를 후보로 생각할 수 있다. 얼마나 IO-bound 인지에 따라 다르기 때문에 경험적으로 찾을 수 밖에 없다. IO-bound task 의 경우는 CPU-bound task 보다 더 여유롭게 스레드 풀의 스레드 개수를 가져갈 수 있다는 점이 중요하다.
스레드 풀에서 실행될 task 개수에 제한이 없다면?
스레드 풀의 큐가 사이즈 제한이 있는지 꼭 확인해야 한다.
요청이 끊임 없이 들어오는 백엔드 API 서버라고 가정하고 요청이 엄청나게 많이 들어오게 되면, 더 이상 작업을 수행할 스레드가 없기 때문에 큐에 요청이 쌓이게 될텐데 이때 큐 사이즈에 제한이 없다면 요청이 무한정 쌓이게 될 것이다.
위 현상은 잠재적으로 시스템의 메모리를 고갈시킬 수 있는 위험 요인이 된다.
따라서 스레드 풀의 큐가 사이즈 제한이 없다면 반드시 제한을 두어서 큐의 사이즈 제한을 넘는 요청은 안타깝지만 버리더라도 전체 시스템에 문제가 생기는 것을 방지해야 한다.
자바의 Executors 클래스
Java 1.5 부터는 `Executors` 클래스의 여러 가지 static 메서드를 통해 다양한 형태의 스레드 풀을 제공한다.
ExecutorService threadPool = Executors.newFixedThreadPool(10);
threadPool.submit(task1);
threadPool.submit(task2);이렇게 스레드 개수가 10개로 고정된 스레드 풀을 만들 수 있고 submit 메서드를 통해 task 들을 할당 할 수 있다.
그런데 이렇게 생성된 스레드 풀의 작업 큐 사이즈는 어떻게 될까?
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}`newFixedThreadPool`의 소스 코드를 보니 `new LinkedBlockingQueue<Runnable>()`를 통해 작업 큐를 만드는 것을 확인 할 수 있다.
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}LinkedBlockingQueue를 만드는 생성자 메서드를 찾아가 보니 `Integer.MAX_VALUE`를 파라미터로 넣는 같은 이름의 생성자를 호출한다. 다시 한번 생성자를 찾아가보겠다.
public LinkedBlockingQueue(int capacity) {
if (capacity <= 0) throw new IllegalArgumentException();
this.capacity = capacity;
last = head = new Node<E>(null);
}자바에서 Integer.MAX_VALUE는 21억이 넘는 값으로 이 값을 큐의 capacity로 전달하는 말은 사실상 큐 사이즈 제한이 없다는 말이다.
따라서 `Executors.newFixedThreadPool()`을 통해 만들어진 스레드 풀에 요청이 많이 몰리게 되었을 때 큐에 계속 요청이 쌓이게 되어서 메모리 이슈로 시스템 장애 요인이 될 수 있다.
자바에서 기본적으로 제공하는 메서드니까 안심하고 쓰면 되겠지라고 생각하고 사용하면 안되고 해당 메서드의 위험 요인을 인식하고 있어야 한다.
마치며
스레드 풀을 사용한다는건 스레드를 활용해 병렬적인 작업을 처리한다는 내용이기 때문에 동시성 이슈를 잘 고려해야 한다. 해당 내용은 필자가 작성한 다음 포스팅을 참고하면 참고가 될 것이다.
동기화(synchronization)와 Thread Safe 제대로 이해하기
동기화(synchronization)와 Thread Safe 제대로 이해하기
싱글스레드 프로세스의 경우 프로세스 내에서 단 하나의 스레드만 작업하기 때문에 프로세스의 자원을 가지고 작업하는데 별문제가 없지만, 멀티스레드 프로세스의 경우 여러 스레드가 같은
castlejune.tistory.com
'Java' 카테고리의 다른 글
| Java Off-heap Memory Leak 원인을 찾아서 (0) | 2026.01.03 |
|---|---|
| Java에서 Enum 의 비교는 '==' 인가? 'equals' 인가? (1) | 2022.03.20 |
| 자바와 다중상속 문제 (0) | 2022.01.08 |
| 자바8 람다식의 등장 (0) | 2022.01.02 |
| 동기화(synchronization)와 Thread Safe 제대로 이해하기 (5) | 2021.12.26 |




댓글